🧐 Gradient Descent Learning 이란?
Input을 넣었을 때 우리가 원하는 Output을 얻기 위해서는 그에 맞는 함수를 찾아야 한다.

알맞은 Output이 나오도록 하는 F(x)를 찾기 위해서 우리는 컴퓨터에 학습(Learning)을 시켜준다.
( Perceptrone에서는 F(x)를 찾는다는 것은 Weight들을 찾는 것을 의미한다. )
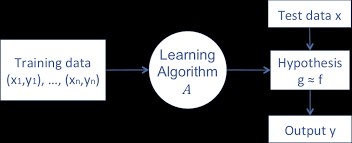
위와 같이 알고리즘에 Training Data를 넣은 결과와 예상되는 Target Answer를 비교한다.
비교한 결과에 따라 학습을 시켜주며 모든 값이 Target Answer와 동일하도록 반복하며 학습시킨다.
이런 과정 속에 틀린 값, 즉 Error들이 나올 수 있는데
어떻게 하면 이 Error를 최소화시킬 수 있을까?
일단 Error를 구해보자.
Error를 구하기 위해서는 전체 테스트 해야할 정답의 수에서 맞은 정답의 수를 빼주면 된다.
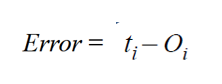
방정식의 극소점을 구해주기 위해서는 미분을 한 후 0이 되는 값을 찾아주면 된다.
하지만 에러 값은 양수가 나올 수 있고 음수도 나올 수 있다.
음수가 나와 계산에 번거로움을 없애주기 위해 Error의 식을 변경해줘야 한다.
우리는 보통 음수에서 양수를 만들어주기 위해 절댓값을 붙여 해결하곤 하지만,
그러나 절댓값은 복잡한 식일 때 미분함에 있어서 어려움을 줄 수 있다.
따라서 절댓값을 씌어주는 대신 아래와 같이 식을 변경을 해야 한다.
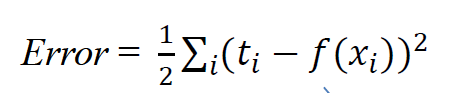
우리는 임의의 weight 값을 넣어주고 학습을 시켜 에러율을 최소화시켜야 한다.
Error가 최소로 나오게 하기 위해 weight 값들을 움직이며 극소점을 찾아줘야 하는데,
이때 Gradient descent ( 경사 하강법 )을 통해 극소점이 나오기 위한 weight 값들을 유추할 수 있다.
Gradient descent란 말 그대로 경사가 하강하는 곳으로 값을 변경해주는 방법이다.
- 기울기가 음수라면 weight값은 높여줘야 하고, ( Gradient < 0 -> direction of weight : + )
- 기울기가 양수라면 weight값은 낮혀야한다. ( Gradient > 0 -> direction of weight : - )
이것을 사용하면 경사가 하강하고 경사가 상승하는 부분에 최솟값이 나오는 것을 알 수 있다.

위 그림과 같이 손쉽게 Error가 최솟값이 나올 수 있도록 하기 위한 weight값들을 유추할 수 있다.
📃 정리
퍼셉트론(Perceptron)에서 Error를 최솟값으로 만들어주기 위해 각 w값들에 대해 편미분을 하며 값을 구해줘야 한다.
( ※ 다층 퍼셉트론이라면 편미분을 BackPropagation Algorithm을 통해 쉽게쉽게 해결하자)
즉, 아래와 같은 퍼셉트론일 때 최소 Error 값을 구해주기 위해,
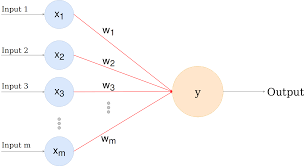
각 가중치(w1, w2, w3.... wm)마다 편미분을 시행해 각 가중치의 최솟값을 찾는 방법을 반복하며 학습시키자!

궁금하신 것이 있으시면 언제든지 댓글 달아주세요!

'Artificial Intelligence' 카테고리의 다른 글
| [A.I] Learning ( 학습 ) (0) | 2020.10.06 |
|---|---|
| [A.I] Non-linear Problem을 Linear Problem으로 바꿔주기 (0) | 2020.09.14 |
